MIRAGE-Bench Observations

Figure 1: A multilingual RAG pipeline in the Hindi language. The question asks "how many letters are there in binary code?" and the correct answer generated is "binary code contains two letters."

Figure 2: Lollipop plots plotting the average heuristic-based feature scores achieved by RAG systems in MIRAGE-Bench. Each model is grouped within the same family (e.g., Meta).
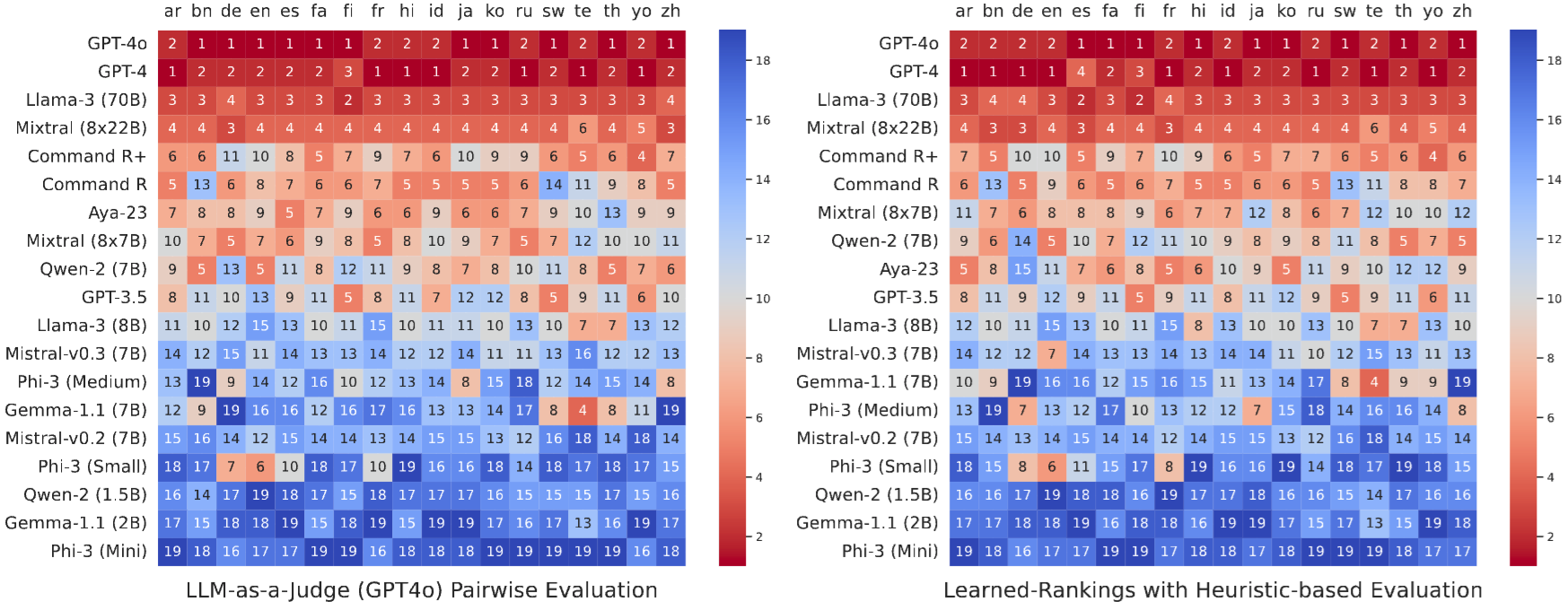
Figure 3: Heatmap showing the rank achieved by LLMs on MIRAGE-Bench using LLM-as-a-Judge pairwise comparisons (left) and using surrogate judge scores (right). Kendall tau correlation achieved = 0.909.
Quantitative Analysis: MIRAGE-Bench synthetic leaderboard by training a surrogate judge observes a high correlation (Kendall Tau = 0.909) with GPT-4o based LLM-as-a-Judge leaderboard, indicating the effectiveness of the random forest model acting as a surrogate judge.
Heatmaps: We observed that closed-sourced and large multilingual-focused LLMs dominate multilingual generation, GPT-4 and GPT-4o currently dominate answering questions in MIRACL, next topmost open-weights model is the Meta-Llama-3-70B model.
Benchmarking: MIRAGE-Bench evaluates 21 multilingual-focused LLMs on 18 languages. The benchmark is cost-effective and extensible, as it only requires training a surrogate judge to evaluate RAG systems on heuristic-based features. The surrogate judge can be retrained within minutes on a CPU when presented with newer features or additional systems for evaluation.